Bereits seit anderthalb Jahren vergeben wir nun einen Preis für die beste User-News des Monats. User-News sind Computer-Nachrichten aus aller Welt, die nicht von einem Planet 3DNow! Team-Mitglied recherchiert, aufbereitet und veröffentlicht wurden, sondern von einem "normalen" Besucher des Forums. Dafür gibt es auf Planet 3DNow! eine separate Sektion im Forum namens User-News. Dort können Leser selbst News posten wenn sie der Meinung sind, das könnte für die Community ganz interessant sein. Die letzten beiden User-News erscheinen auch immer auf der Startseite.
Aber wie misst man nun, welche davon die beste des Monats war? Hier hatten für uns für die Danke-Funktion als Gradmesser entschieden:
Gute Beiträge können von den übrigen Lesern per Danke-Knopf honoriert werden. Der User, der am meisten "Dankes" gesammelt hat, ist der Sieger. Das ist auch der Grund, weshalb wir die Auswertung erst jetzt, weit im Folgemonat, machen; damit die Ende des Monats geposteten User-News keinen Nachteil haben. Und wer hat nun gewonnen?
Es ist Emploi, herzlichen Glückwunsch! Dafür gibt's als Anerkennung ein Tasse aus der Planet 3DNow! Collection:
Offenbar hat sich AMD dazu entschlossen, den altbekannten monatlichen Rhythmus für die Aktualisierung der WHQL-Treiber zu beenden. Dadurch will das Unternehmen den Fokus verstärkt auf eine höhere Qualität der einzelnen Releases legen. Es existiert zwar noch keine entsprechende offizielle Erklärung von AMD, allerdings hat der Catalyst-Beta-Tester LordJuanlo im Forum von Rage3D eine solche für den heutigen Tag angekündigt. Welche Konsequenzen diese Entscheidung für die Legacy-Produkte hat, ist bisher unbekannt.
Zudem nennt LordJuanlo weitere Details und Konsequenzen zu dieser einschneidenden Entscheidung: So wird es diesen Monat keinen neuen Treiber und damit auch keinen Catalyst 12.5 WHQL mehr geben. An Stelle der monatlichen WHQL-Releases wird es künftig häufiger Hotfix- und Preview-Treiber geben, mit denen Anpassungen für aktuelle Spiele-Veröffentlichungen und dringende Bugfixes ausgeliefert werden sollen. Der Qualitätsgewinn soll vor allem daraus resultieren, dass es nicht länger notwendig ist, mehrere Treiber-Pfade parallel zu entwickeln. Bisher wurde immer ein Treiber-Pfad zur WHQL-Reife gebracht, während parallel bereits die Entwicklung für die nächsten Releases lief.
Abschließend stellt LordJuanlo einen neuen Beta-Treiber für die nächste Woche in Aussicht, der zumindest auf den Southern-Islands-GPUs das Tearing beheben soll, welches bisher auf Eyefinity-Systemen mit drei Bildschirmen zu beobachten war, wenn die Monitore mit unterschiedlichen Anschlusstypen verbunden sind - also nicht ausschließlich über DisplayPort.
Die News wird aktualisiert, sobald uns die offizielle Erklärung von AMD vorliegt.
Zitat: LordJuanlo
There should be a public announcement today, but I have been allowed to share this info right now:
- AMD will end monthly Catalyst driver releases starting with Catalyst 12.5 (which won't exist). They have decided to focus harder on quality and improvements vs regular updates which may not bring many new things. This way there will be no need for two separate driver development paths every month: one to get the official WHQL driver and another that keeps doing the regular driver development. - We should expect more "hot fixes" and "preview drivers" when new games are released or urgent fixes are required. - There is a beta driver we are testing right now that fixes the Eyefinity tearing on the third monitor when mixing outputs. I have verified that it works with Souther Islands based cards, so I don't know if it will work with previous cards. Anyway, if no major issues are found, this driver should be publicly available next week.
Mittlerweile hat AMD auch offiziell in den Release Notes des Catalyst 12.6 Beta Stellung bezogen. Demnach beendet AMD den monatlichen Update-Zyklus mit dem Ziel, dass künftig jeder Catalyst-Release substantielle Verbesserungen für die Kunden mit sich bringen soll und eben nicht nur eine höhere Versionsnummer. An der Namensgebung (Catalyst Jahr.Monat) der einzelnen Versionen will das Unternehmen hingegen nichts verändern. Es wird aber nicht jeden Monat einen neuen WHQL-Treiber geben.
Zu guter Letzt weist AMD noch auf das überarbeitete, offizielle AMD Issue Reporting Form hin, welches Kunden nutzen können, um das Treiber-Team über Problem zu informieren. Eine Hilfestellung für das Formular könnt Ihr hier finden.
Zitat: AMD
With the release of the AMD Catalyst 12.6 Beta driver (Catalyst), AMD would also like to announce that we are moving away from our Monthly Catalyst release plan. Our goal is to ensure that every Catalyst release delivers a substantial benefit to our end users; as we have today with the release of the Catalyst 12.6a Beta. We will still continue with the Catalyst naming convention; Catalyst: Year.Month. You just wont see a new driver every single month. We are confident that this will only benefit the end user; youll only need to upgrade to a new Catalyst driver, when it makes sense.
We would also like to announce the introduction of our new AMD Issue Reporting Form. We made a number of improvements to the older Catalyst Crew Feedback form, making it more comprehensive, ensuring high quality feedback. Feedback is very important in every product companys life, especially in our fast paced environment. This is not just a check-box for us we take these reports very seriously. We will review every report posted here and investigate every issue encountered. Please use this form whenever you encounter something worth mentioning.
Wie Listan in einer Pressemitteilung bekannt gab, wird unter dem Namen be quiet! demnächst die Dark-Power-Pro-P10-Serie auf den Markt gebracht. Bei den Dark Power Pro handelt es sich um die teuersten PC-Netzteile des Anbieters, die sich qualitativ von den anderen Baureihen (Pure Power, Straight Power) abgrenzen sollen. Bereits auf der Computex 2011 wurde die aktuellste Revision P10 angekündigt, erst jetzt erreicht die Serie aber ihren finalen Status.
In Bälde sollen die Modelle 550 CM, 650 CM, 750 CM, 850 CM, 1000 CM und 1200 CM erhältlich sein. Lediglich das 850-W-Gerät (850 CM) wurde mit 80 PLUS Platinum ausgezeichnet, während die anderen über das 80-PLUS-Gold-Zertifikat verfügen. Sämtliche Modelle werden mit einem Silent-Wings-Lüfter ausgestattet (135 mm). Zudem betont Listan, mit dem Resonanzwandler und den Tiefsetzstellern auf aktuelle Technologien zurückgegriffen zu haben. Nicht zuletzt wird den Netzteilen der sogenannte Overclocking-Key beigelegt, mit dem wahlweise zwischen einer "Single-Rail" oder "Multi-Rails" auf dem +12-V-Ausgang umgeschaltet werden kann.
Vor kurzem haben wir unseren ersten vollständigen Test über einen 19-V-Adapter für Notebooks veröffentlicht. Heute stellen wir zwei weitere Modelle von be quiet! und Thermaltake vor, die wie das Gerät von FSP auch über einen USB-Anschluss verfügen. Eine Besonderheit des be quiet! Notebook Power 90 W sind die einstellbaren Ausgangsspannungen. Das Thermaltake ToughPower Ultra Slim 90 W punktet dafür mit einem geringeren Preis. Welches Produkt für welchen Anwender das bessere ist, werden wir auf den folgenden Seiten klären. Wie immer wünschen wir viel Spaß beim Lesen des Artikels!
Nachdem wir bereits im letzten Jahr aufdecken mussten, dass AMD widersprüchliche Angaben zur Transistorenanzahl auf dem "Orochi"-Die gemacht hatte, ist ihnen offenbar erneut ein Missgeschick unterlaufen. Denn auch für den "Llano"-Die existieren seit dem Launch der zweiten APU-Generation ("Trinity") zwei erheblich voneinander abweichende Angaben. Offenbar hat sich AMD erneut um 272 Mio. Transistoren verzählt, sodass der ursprüngliche Wert von 1,45 Mrd. auf 1,178 Mrd. korrigiert werden musste. Diese Abweichung von fast 20% ist zwar bei weitem nicht so extrem, wie die 40% beim "Orochi"-Die, wirft aber erneut kein gutes Licht auf die Vertrauenswürdigkeit der Unternehmenskommunikation.
Uns war diese Abweichung zwar bereits aufgefallen, allerdings kannten wir bisher lediglich als Quelle für die alte Angabe einen Artikel von AnandTech vom 14. Juni 2011. In sämtlichem uns bekannten Pressematerial sprach AMD hingegen lediglich recht vage von ungefähr einer Milliarde Transistoren, weshalb wir bisher von einem damaligen Missverständnis ausgingen.
Wie Bright Side Of News jetzt allerdings aufzeigt, wurde die alte Angabe am 19. August 2011 auf der Hot-Chips-Konferenz, einer der wichtigsten Veranstaltungen in der Halbleiterindustrie mit den Schwerpunkten High-Performance Mikroprozessoren und zugehörigen integrierten Schaltungen, nochmals bestätigt. In der Präsentation "AMD's Llano Fusion APU" nennen die Ingenieure von AMD erneut eine Transistorenanzahl von 1,45 Mrd. bei einer Die-Größe von 227 mm² für den "Llano"-Die.
Damit bleibt fragwürdig, welche Aussage der Wahrheit am nächsten kommt. Letztlich sollte sich jeder darüber im Klaren sein, dass die exakten Die-Größen sowie Transistorenanzahl und damit letztlich die erreichte Packungsdichte genauso zu den Firmengeheimnissen gehören, wie die erreichte Ausbeute in der Fertigung. Schließlich sind diese Werte von elementarer Bedeutung für die Wirtschaftlichkeit und damit Konkurrenzfähigkeit eines Unternehmens in der Halbleiterindustrie. Was der Presse an Werten genannt wird, sind also immer nur Näherungen. In der nachfolgenden Tabelle haben wir nochmals die (nach aktuellem Stand) bekannten Daten für 32nm-Prozessoren der beiden Hauptkonkurrenten im x86-Markt gegenübergestellt. Die zuvor für den "Llano"-Die errechneten 6,36 Mio. Transistoren pro Quadratmillimeter erschienen schon immer erstaunlich hoch, auch wenn der Fertigungspartner GlobalFoundries für den Gate-Last-Prozess der Konkurrenz einen ca. zehnprozentigen Nachteil bei der Die-Größe gegenüber dem eigenen Gate-First-Ansatz veranschlagt. Mit der korrigierten Transistorenanzahl nähert sich AMD der Packungsdichte von Intel an.
Wir haben bei AMD nachgefragt, welcher Wert denn nun stimmt und um eine Erklärung für die widersprüchlichen Angaben gebeten.
Wir haben inzwischen eine Antwort von AMD erhalten, die nachfolgend im Wortlaut zu finden ist. Demnach sind offenbar sowohl die auf der Hot Chips genannten 1,45 Mrd. als auch die vermeintlich korrigierte Anzahl von 1,178 Mrd. Transistoren richtig. Als Grund für die Diskrepanz wird eine geänderte Methodik genannt, nach der die Transistorenanzahl bestimmt wird. Mit dieser überarbeiteten Zählweise, die seit 2012 angewendet wird, will das Unternehmen sicherstellen, dass die Konsistenz zwischen den einzelnen Veröffentlichungen gewährleistet ist. In der ursprünglich genannten Zahl sind sämtliche damals für das Design verwendeten Transistoren enthalten, wohingegen nach der neuen Methodik sämtliche Entkopplungskondensatoren (decoupling capacitors) auf dem Chip nicht mehr berücksichtigt werden. Stattdessen wird lediglich die Transistorenanzahl der Flat-Device angegeben.
Solche Entkoppelungstransitoren kommen in elektrischen Schaltungen zum Einsatz, um das Rauschen und damit die Betriebsspannungsschwankungen zu minimieren. Sie verhindern also, dass Störimpulse, die durch das schnelle Schalten digitaler Baugruppen verursacht werden, zu anderen Funktionsblöcken gelangen und umgekehrt. Wenn die Ingenieure beim Design des finalen Dies sämtliche Funktionsblöcke zusammenschalten ergeben sich dann Redundanzen und Wechselwirkungen, die von den Simulationstools nur unzureichend berücksichtigt werden. Eine Optimierung ist nur durch aufwendiges, iteratives, manuelles Ersetzen oder Entfernen der Entkopplungskondensatoren durch einen Ingenieur und anschließende Überprüfung des Ergebnisses möglich. Somit kann sich die Transistorenanzahl innerhalb der Optimierungsphase also noch erheblich verändern, obwohl es am eigentlichen Design keine Änderungen gibt.
Zitat: AMD
"Beginning in 2012, AMD updated its methodology for transistor counts to ensure consistency. The numbers provided for our recent Trinity launch (and all disclosures moving forward) are based on a flat device count minus de-capacitor cells. The numbers that were provided at last years Hot Chips conference were based on flat device + de-cap cells."
Ende 2011 stellte SilverStone das Precision PS07 vor, welches als erstes Gehäuse der Precision-Serie keine ATX-Boards, sondern lediglich mATX-, DTX- und mITX-Boards aufnehmen kann. Vor einigen Tagen schließlich legte SilverStone das PS07W nach. Das W in der Produktbezeichnung steht für Weiß. Nachdem wir in letzter Zeit verstärkt Gaming-Gehäuse getestet haben, ist dies ein Grund mehr, sich das neue Modell genauer anzuschauen, immerhin gibt es in weiß deutlich weniger Gehäuseauswahl als in schwarz.
Die Erwartungen der Redaktionen an Gehäuse von SilverStone sind sicherlich höher als bei anderen Herstellern, nicht umsonst gehört SilverStone mit zu den bekannteren Herstellern im Gehäusebereich. Grund hierfür ist die hohe Verarbeitungsqualität, verbunden mit edlem Aluminium. Die Temjin-Reihe, speziell das Temjin TJ-07, gehört noch heute zu den beliebtesten Gehäusen und erzielt auch im Gebrauchtmarkt noch oft Preise, die nur knapp unter dem Neupreis liegen. Aber nicht jeder Käufer ist bereit, 200 Euro oder mehr für ein Gehäuse zu bezahlen und so musste nach und nach Aluminium Kunststoff beziehungsweise Stahlblech weichen. Trotz der vergleichsweise günstigen Materialien bleibt die Qualität gewohnt gut und immer noch überrascht SilverStone mit kleinen ausgefallenen Extras oder üppigem Zubehör.
Wir bedanken uns bei SilverStone für das Testmuster und wünschen viel Spaß beim Lesen.
Nachdem wir bereits im letzten Jahr aufdecken mussten, dass AMD widersprüchliche Angaben zur Transistorenanzahl auf dem "Orochi"-Die gemacht hatte, ist ihnen offenbar erneut ein Missgeschick unterlaufen. Denn auch für den "Llano"-Die existieren seit dem Launch der zweiten APU-Generation ("Trinity") zwei erheblich voneinander abweichende Angaben. Offenbar hat sich AMD erneut um 272 Mio. Transistoren verzählt, sodass der ursprüngliche Wert von 1,45 Mrd. auf 1,178 Mrd. korrigiert werden musste. Diese Abweichung von fast 20% ist zwar bei weitem nicht so extrem, wie die 40% beim "Orochi"-Die, wirft aber erneut kein gutes Licht auf die Vertrauenswürdigkeit der Unternehmenskommunikation.
Uns war diese Abweichung zwar bereits aufgefallen, allerdings kannten wir bisher lediglich als Quelle für die alte Angabe einen Artikel von AnandTech vom 14. Juni 2011. In sämtlichem uns bekannten Pressematerial sprach AMD hingegen lediglich recht vage von ungefähr einer Milliarde Transistoren, weshalb wir bisher von einem damaligen Missverständnis ausgingen.
Wie Bright Side Of News jetzt allerdings aufzeigt, wurde die alte Angabe am 19. August 2011 auf der Hot-Chips-Konferenz, einer der wichtigsten Veranstaltungen in der Halbleiterindustrie mit den Schwerpunkten High-Performance Mikroprozessoren und zugehörigen integrierten Schaltungen, nochmals bestätigt. In der Präsentation "AMD's Llano Fusion APU" nennen die Ingenieure von AMD erneut eine Transistorenanzahl von 1,45 Mrd. bei einer Die-Größe von 227 mm² für den "Llano"-Die.
Damit bleibt fragwürdig, welche Aussage der Wahrheit am nächsten kommt. Letztlich sollte sich jeder darüber im Klaren sein, dass die exakten Die-Größen sowie Transistorenanzahl und damit letztlich die erreichte Packungsdichte genauso zu den Firmengeheimnissen gehören, wie die erreichte Ausbeute in der Fertigung. Schließlich sind diese Werte von elementarer Bedeutung für die Wirtschaftlichkeit und damit Konkurrenzfähigkeit eines Unternehmens in der Halbleiterindustrie. Was der Presse an Werten genannt wird, sind also immer nur Näherungen. In der nachfolgenden Tabelle haben wir nochmals die (nach aktuellem Stand) bekannten Daten für 32nm-Prozessoren der beiden Hauptkonkurrenten im x86-Markt gegenübergestellt. Die zuvor für den "Llano"-Die errechneten 6,36 Mio. Transistoren pro Quadratmillimeter erschienen schon immer erstaunlich hoch, auch wenn der Fertigungspartner GlobalFoundries für den Gate-Last-Prozess der Konkurrenz einen ca. zehnprozentigen Nachteil bei der Die-Größe gegenüber dem eigenen Gate-First-Ansatz veranschlagt. Mit der korrigierten Transistorenanzahl nähert sich AMD der Packungsdichte von Intel an.
Wir haben bei AMD nachgefragt, welcher Wert denn nun stimmt und um eine Erklärung für die widersprüchlichen Angaben gebeten.
Wir haben inzwischen eine Antwort von AMD erhalten, die nachfolgend im Wortlaut zu finden ist. Demnach sind offenbar sowohl die auf der Hot Chips genannten 1,45 Mrd. als auch die vermeintlich korrigierte Anzahl von 1,178 Mrd. Transistoren richtig. Als Grund für die Diskrepanz wird eine geänderte Methodik genannt, nach der die Transistorenanzahl bestimmt wird. Mit dieser überarbeiteten Zählweise, die seit 2012 angewendet wird, will das Unternehmen sicherstellen, dass die Konsistenz zwischen den einzelnen Veröffentlichungen gewährleistet ist. In der ursprünglich genannten Zahl sind sämtliche damals für das Design verwendeten Transistoren enthalten, wohingegen nach der neuen Methodik sämtliche Entkopplungskondensatoren (decoupling capacitors) auf dem Chip nicht mehr berücksichtigt werden. Stattdessen wird lediglich die Transistorenanzahl der Flat-Device angegeben.
Solche Entkoppelungstransitoren kommen in elektrischen Schaltungen zum Einsatz, um das Rauschen und damit die Betriebsspannungsschwankungen zu minimieren. Sie verhindern also, dass Störimpulse, die durch das schnelle Schalten digitaler Baugruppen verursacht werden, zu anderen Funktionsblöcken gelangen und umgekehrt. Wenn die Ingenieure beim Design des finalen Dies sämtliche Funktionsblöcke zusammenschalten ergeben sich dann Redundanzen und Wechselwirkungen, die von den Simulationstools nur unzureichend berücksichtigt werden. Eine Optimierung ist nur durch aufwendiges, iteratives, manuelles Ersetzen oder Entfernen der Entkopplungskondensatoren durch einen Ingenieur und anschließende Überprüfung des Ergebnisses möglich. Somit kann sich die Transistorenanzahl innerhalb der Optimierungsphase also noch erheblich verändern, obwohl es am eigentlichen Design keine Änderungen gibt.
Zitat: AMD
"Beginning in 2012, AMD updated its methodology for transistor counts to ensure consistency. The numbers provided for our recent Trinity launch (and all disclosures moving forward) are based on a flat device count minus de-capacitor cells. The numbers that were provided at last years Hot Chips conference were based on flat device + de-cap cells."
Bereits in der Nacht von Freitag auf Samstag um 2:00 Uhr endete der dritte BOINC-Pentathlon, der dem Andenken an das kürzlich verstorbenen langjährigen Team-Mitglied Jip vom Team l'Alliance Francophone gewidmet war. Unser Distributed-Computing-Team (DC-Team) vom grünen Planeten konnte durch eine herausragende Team-Leistung den überraschenden zweiten Platz des Vorjahres toppen und den diesjährigen modernen Fünfkampf sogar für sich entscheiden. Mit 20 Punkten Vorsprung konnten wir SETI.Germany und SETI.USA auf den zweiten Platz verweisen, den sich die beiden Teams punktgleich teilen müssen. Wie es bereits im letzten Jahr zu beobachten war, profitierte unser DC-Team erneut vor allem von der Fähigkeit, kurzfristig eine enormer Rechenleistung mobilisieren und geschickt auf die einzelnen Teildisziplinen verteilen zu können. Nur so war es möglich, an Mitgliedern viel stärkere Teams wie SETI.Germany, SETI.USA oder Team 2ch zu übertrumpfen.
Beim BOINC-Pentathlon 2012 gewonnener Medaillen-Satz
Hoch motiviert vom zweiten Platz im Vorjahr ging unser DC-Team in den dritten BOINC-Pentathlon und setzte so bereits zum Auftakt ein Ausrufezeichen. Bei Rosetta@home, der ersten Teildisziplin des Pentathlon aus der Kategorie Biologie & Medizin, katapultierte sich Planet 3DNow! vom Start weg direkt auf den ersten Platz und konnte diesen bis zum Schluss auch halten. Den Grundstein für den Erfolg beim "modernen Fünfkampf" legte dann das Team in der einzigen GPU-Disziplin Collatz Conjecture. Hier glühten die Grafikkarten unserer Mitglieder, um mit der Silbernen die erste GPU-Medaille bei einem Pentathlon zu holen. Dies ist besonders bemerkenswert, da unser Team in den Vorjahren gern wegen einer vermeintlichen Grafikkarten-Schwäche belächelt wurde. Im dritten Projekt World Community Grid (Showbag) nahm sich das Team dann eine kleine Verschnaufpause (sechster Platz), um sich für den Endspurt bei den abschließenden CPU-Projekten yoyo@home (Mathematik) und QMC@HOME (Physik & Chemie) - der Paradedisziplin von Planet 3DNow! - vorzubereiten, die parallel gerechnet wurden. Diese Zeit wurde für den Aufbau von großen "Bunkern" in beiden Projekten genutzt. Hierzu rechneten die Teammitglieder bereits vor dem eigentlichen Startschuss der Projekte Work-Units (WUs) auf Halde, die dann auf einen Schlag abgeliefert werden konnten. Dadurch erarbeitete sich unser Team einen Vorsprung, den die anderen Teams bis zum Schluss nicht einholen konnten. Weil unsere beiden Hauptkonkurrenten in der Gesamtwertung SETI.Germany und SETI.USA bis zum Schluss in Schlagdistanz lagen, hielten sich lange Zeit Befürchtungen, beide könnten Pokern und erst kurz vor dem Finale ihre großen "Bunker-Tore" öffnen. Nicht zuletzt die angesichts der jeweiligen Teamgröße erstaunlich geringe stündliche Punkteausbeute schürte solche Spekulationen, sodass die nervenzerreißende Anspannung im Race-Thread zum greifen war. Um 2:00 Uhr war dann allerdings klar, dass sich diese Befürchtungen glücklicherweise nicht bewahrheiteten. Das DC-Team von Planet 3DNow! konnte seinen ersten Sieg beim BOINC-Pentathlon feiern.
Planet 3DNow! gratulieren SETI.Germany und SETI.USA, die punktgleich den zweiten Platz in der Gesamtwertung erringen konnten. Mehr zum höchst spannenden Verlauf des BOINC-Pentathlon 2012 kann in den täglichen Berichten von Jeeper74 nachgelesen werden.
Wir Danken allen Klein- und Groß-Crunchern, lange Zeit verschollenen Teammitgliedern und ganz besonders unserer "Geheimwaffe" UTG für ihre Mithilfe sowie für die tolle Stimmung im Race-Thread, der mittlerweile über 4100 Posts umfasst! Unser Dank gilt aber auch dem Veranstalter SETI.Germany für die tolle Organisation und allen teilnehmenden Teams für den spannenden Wettstreit. Wir vom grünen Planeten freuen uns jedenfalls auf die Neuauflage im nächsten Jahr und dem damit verbundenen Projekt Titelverteidigung. Spätestens ab dem 5. Mai 2013 wird es dann wieder heißen:
"Wir brauchen mehr POWER!"
Wer am Distributed Computing Gefallen gefunden hat und nach neuen Aufgaben sucht, der wird sicherlich bei uns im DC-Forum fündig. Dort sind sämtliche Projekte zu finden, bei denen wir ein Team haben, samt weiterer Informationen.
Nach einer kleineren Verzögerung hat gestern Abend auch die abschließende feierliche Ehrung für die Gesamtwertung auf der "Medals Plaza" stattgefunden. In der Würdigung schreibt der Veranstalter SETI.Germany treffend:
Zitat:
"Mit drei Siegen legten sie den Grundstein für den Erfolg. Nur bei WCG mussten die Grünen Federn lassen, hier scheint die Achillesferse zu sein. Glück für P3D, dass die Verfolger diese Schwäche nicht ausnutzen konnten. Sie schafften es am besten ihre Mitglieder und mehr zu mobilisieren, diese Stärke war die Grundlage für den Sieg. Auch taktisch ließen sie sich nicht zu Fehlern hinreißen und auch das Glück war ihnen hold, denn der kurze Ausfall von QMC dürfte vor allem die Strategie der Verfolger durcheinandergebracht haben. Kurz: Alles richtig gemacht."
Dem bleibt auch nichts mehr hinzuzufügen. Und da ist sie, die hoch verdiente Goldmedaille für die beste Team-Leistung beim dritten BOINC-Pentathlon:
Bereits in der Nacht von Freitag auf Samstag um 2:00 Uhr endete der dritte BOINC-Pentathlon, der dem Andenken an das kürzlich verstorbenen langjährigen Team-Mitglied Jip vom Team l'Alliance Francophone gewidmet war. Unser Distributed-Computing-Team (DC-Team) vom grünen Planeten konnte durch eine herausragende Team-Leistung den überraschenden zweiten Platz des Vorjahres toppen und den diesjährigen modernen Fünfkampf sogar für sich entscheiden. Mit 20 Punkten Vorsprung konnten wir SETI.Germany und SETI.USA auf den zweiten Platz verweisen, den sich die beiden Teams punktgleich teilen müssen. Wie es bereits im letzten Jahr zu beobachten war, profitierte unser DC-Team erneut vor allem von der Fähigkeit, kurzfristig eine enormer Rechenleistung mobilisieren und geschickt auf die einzelnen Teildisziplinen verteilen zu können. Nur so war es möglich, an Mitgliedern viel stärkere Teams wie SETI.Germany, SETI.USA oder Team 2ch zu übertrumpfen.
Beim BOINC-Pentathlon 2012 gewonnener Medaillen-Satz
Hoch motiviert vom zweiten Platz im Vorjahr ging unser DC-Team in den dritten BOINC-Pentathlon und setzte so bereits zum Auftakt ein Ausrufezeichen. Bei Rosetta@home, der ersten Teildisziplin des Pentathlon aus der Kategorie Biologie & Medizin, katapultierte sich Planet 3DNow! vom Start weg direkt auf den ersten Platz und konnte diesen bis zum Schluss auch halten. Den Grundstein für den Erfolg beim "modernen Fünfkampf" legte dann das Team in der einzigen GPU-Disziplin Collatz Conjecture. Hier glühten die Grafikkarten unserer Mitglieder, um mit der Silbernen die erste GPU-Medaille bei einem Pentathlon zu holen. Dies ist besonders bemerkenswert, da unser Team in den Vorjahren gern wegen einer vermeintlichen Grafikkarten-Schwäche belächelt wurde. Im dritten Projekt World Community Grid nahm sich das Team dann eine kleine Verschnaufpause (sechster Platz), um sich für den Endspurt bei den abschließenden CPU-Projekten yoyo@home und QMC@HOME - der Paradedisziplin von Planet 3DNow! - vorzubereiten, die parallel gerechnet wurden. Diese Zeit wurde für den Aufbau von großen "Bunkern" in beiden Projekten genutzt. Hierzu rechneten die Teammitglieder bereits vor dem eigentlichen Startschuss der Projekte Work-Units (WUs) auf Halde, die dann auf einen Schlag abgeliefert werden konnten. Dadurch erarbeitete sich unser Team einen Vorsprung, den die anderen Teams bis zum Schluss nicht einholen konnten. Weil unsere beiden Hauptkonkurrenten in der Gesamtwertung SETI.Germany und SETI.USA bis zum Schluss in Schlagdistanz lagen, hielten sich lange Zeit Befürchtungen, beide könnten Pokern und erst kurz vor dem Finale ihre großen "Bunker-Tore" öffnen. Nicht zuletzt die angesichts der jeweiligen Teamgröße erstaunlich geringe stündliche Punkteausbeute schürte solche Spekulationen, sodass die nervenzerreißende Anspannung im Race-Thread zum greifen war. Um 2:00 Uhr war dann allerdings klar, dass sich diese Befürchtungen glücklicherweise nicht bewahrheiteten. Das DC-Team von Planet 3DNow! konnte seinen ersten Sieg beim BOINC-Pentathlon feiern.
Planet 3DNow! gratulieren SETI.Germany und SETI.USA, die punktgleich den zweiten Platz in der Gesamtwertung erringen konnten. Mehr zum höchst spannenden Verlauf des BOINC-Pentathlon 2012 kann in den täglichen Berichten von Jeeper74 nachgelesen werden.
Wir Danken allen Klein- und Groß-Crunchern, lange Zeit verschollenen Teammitgliedern und ganz besonders unserer "Geheimwaffe" UTG für ihre Mithilfe sowie für die tolle Stimmung im Race-Thread, der mittlerweile über 4100 Posts umfasst! Unser Dank gilt aber auch dem Veranstalter SETI.Germany für die tolle Organisation und allen teilnehmenden Teams für den spannenden Wettstreit. Wir vom grünen Planeten freuen uns jedenfalls auf eine Neuauflage im nächsten Jahr und dem damit verbundenen Projekt Titelverteidigung. Spätestens dann wird es wieder heißen:
"Wir brauchen mehr POWER!"
Wer am Distributed Computing Gefallen gefunden hat und nach neuen Aufgaben sucht, der wird sicherlich bei uns im DC-Forum fündig. Dort sind sämtliche Projekte zu finden, bei denen wir ein Team haben, samt weiterer Informationen.
Lange Zeit war es still im Hause Nanoxia. Mit einer neugestalteten Internetpräsenz und frischen Produkten soll nun angegriffen werden. Während man sich in der Vergangenheit eher auf Zubehör beschränkte, betritt der Hersteller mit dem Deep Silence 1 Neuland. Das Silent-Gehäuse muss sich mit angestammten Konkurrenten messen lassen: Fractal Design Define, Cooler Master Silencio oder auch NZXT H2. Beim Design macht man augenscheinlich keine Experimente. Um trotzdem nicht in der Masse unterzugehen, versucht Nanoxia, mit neuen Ideen Schwung in das Segment zu bringen. Was dahinter steckt, wollen wir uns einmal kurz vor Augen führen.
Auf den ersten Blick ist der Unterschied zu bekannten Produkten tatsächlich gering. Im Gegensatz zu anderen Herstellern setzt Nanoxia auf eine geteilte Front. Das heißt, die 5,25"- und die Frontlüfter sind durch verschiedene Türen verdeckt. Die Innenseite ist selbstverständlich mit einer Dämmmatte versehen, um dem Silent-Anspruch zu genügen. Drei 5,25"-Schächte sind im oberen Bereich zu finden. Die Entnahme der Blenden ist ohne Werkzeug zu bewältigen. Darüber sehen wir eine Zwei-Kanal-Lüftersteuerung und den Reset-Knopf. Im gleichen Atemzug können wir auch noch auf die restlichen Front-Bedienelemente/-Anschlüsse eingehen. Oben sehen wir den großen Power-Knopf. Dahinter ist eine Reihe von Anschlüssen versenkbar, sodass man diese verschwinden lassen kann, wenn sie nicht in Benutzung sind. Das Nanoxia Deep Silence 1 bietet jeweils zwei USB-2.0- und USB-3.0-Buchsen. Hinzu kommen die beiden Front-Audiobuchsen für Kopfhörer und Mikrofon.
Die zweite Tür verbirgt die beiden Frontlüfter. Wie auch man auf dem Bild erkennen kann, soll es möglich sein, ohne Werkzeug diese herauszunehmen und zu reinigen. Staubfilter verhindern das Eindringen größerer Mengen Staub. Eine detaillierte Beschreibung zur Funktionalität des Verschlusses und den einzelnen Schritten zur Demontage findet man in der Produktbeschreibung auf der Homepage. In einer Tabelle findet sich der Hinweis, dass es einen optionalen 3,5"-Schacht geben soll, der auch von außen zugänglich ist.
Aus dieser Perspektive können wir neben dem Innenraum auch noch auf die Rückseite des Gehäuses eingehen. Das Netzteil wird am Boden verbaut und durch einen Staubfilter geschützt, wie man an der unteren Kante sehen kann. Der Filter lässt sich nach hinten herausziehen und reinigen. Das Nanoxia Deep Silence One bietet weiterhin insgesamt vier Schlauchdurchführungen für die Nutzung einer externen Wasserkühlung. Für die Entlüftung kommt an dieser Stelle ein 140-mm-Lüfter zum Einsatz. Der Hersteller bedient sich dabei aus dem eigenen Regal.
Im Innenraum sehen wir diverse Kabeldurchführungen, die für mehr Ordnung sorgen sollen. Die Befestigung der 5,25"-Laufwerke erfolgt werkzeuglos. Die HDD-Käfige des Deep Silence 1 sind modular aufgebaut. Dabei gibt der Hersteller an, dass Gummi-Puffer zum Einsatz kommen, die eine Entkopplung bewirken. Die Montage der 3,5"- oder 2,5"-Laufwerke soll an Einschüben erfolgen. Maximal sind so acht Festplatten möglich. Für die Installation extra-langer Grafikkarten, wie etwa Dual-GPU-Modelle mit ausladenden PCBs und Kühlern, kann beispielsweise der Käfig im Frontbereich herausgenommen werden, sodass nicht nur der Platz für eine Karte auf maximal 445 mm ansteigen soll, sondern auch die direkte Belüftung ermöglicht wird. Hohe Temperaturen sind oftmals das Problem schallgedämmter Gehäuse. Durch die Dämmmatten wird der direkte Wärmeaustausch über die Gehäusewand behindert, was aber nur einen geringen Anteil ausmacht. Viel entscheidender ist die Tatsache, dass die Zahl der Lüfter und deren Öffnungen abnimmt. Jede dieser Öffnungen könnte Ausgangspunkt ungewollter Geräusche sein, weshalb alles möglichst abgedichtet wird.
Um trotzdem für eine verbesserte Entlüftung zu sorgen, hat sich Nanoxia eine Konstruktion im Deckel überlegt. Die im Normalfall schallisolierte Platte kann herausgehoben werden und die warme Abluft kann entweichen. Laut der Produktbeschreibung öffnet sich der Abzug durch einfaches Drücken.
Mit dem Deep Silence 1 hat Nanoxia ein interessantes Produkt in der Mache, das interessante Features mit sich bringt. Auf der Produktseite werden eigentlich alle Fragen beantwortet und man könnte die Beschreibungen fast als Handbuch bezeichnen. Live kann man es auf der in Kürze stattfindenden Computex bewundern. Zu welchem Preis und wann das Gehäuse später erhältlich sein wird, steht noch nicht fest.
Knapp eine Woche ist es her: AMD stellt die zweite Generation der A-Serie-APUs mit dem Codenamen Trinity vor. Nach ersten Berichten in der letzten Woche steht nun offiziell fest, dass die neuen APUs auch im Embedded-Bereich Fuß fassen sollen. Augenscheinlich sind die Produkte auf Basis der kleineren E-Serie so gefragt, dass man an den Erfolg anknüpfen möchte. Größter Vorteil der neuen APUs ist wohl ein Feature, das in diesem Segment einige Kunden begeistern wird: AMD Eyefinity. Bei den neuen APUs der A- und R-Serie hat AMD einige Neuerungen parat. Im Gegensatz zur ersten Generation ist wohl vor allem der Sprung von der älteren K10-Architektur auf die neuere Bulldozer-Architektur hervorzuheben. Als Besonderheit muss man herausheben, dass die neuen APUs auf überarbeitete Module zurückgreifen können. Von AMD werden diese mit dem Codenamen Piledriver betitelt. Da die APUs ohne L3-Cache daherkommen, lässt sich nur bedingt sagen, ob die Leistungsfähigkeit gestiegen ist. Die Leistung pro Takt (IPC-Rate) stellt immer wieder einen Kritikpunkt dar, wenn man die Produkte der Konkurrenz aus dem Hause Intel für Vergleiche heranzieht.
Wenn wir einen Blick auf die Modelle werfen, fällt auf, dass AMD das Angebot recht groß fasst. Für Privatkunden sind nicht so viele unterschiedliche Varianten verfügbar. Vor allem im Ultra-Low-Voltage-Bereich positioniert der kleine x86-Riese mehr Modelle. Die TDP-Limits der R-Serie liegen zwischen 17 und 35 Watt. Dank AMD Turbo Core 3.0 können die Taktraten im Betrieb angehoben werden, solange nicht die TDP-Grenze erreicht wird.
Wenn wir uns die Features ansehen, macht AMD bei den R-Serie-APUs keine großen Unterschiede. Bis auf die kleinste Variante können alle integrierten Grafik-Lösungen beim Encoding von Videomaterial mitarbeiten. Es wäre im Rahmen des Möglichen, dass AMD diese Fähigkeit wie bei den kleinsten APUs der E- bzw. G-Serie gesperrt hat, da die Rechenleistung zu gering ist und keinen nennenswerten Leistungsvorteil bieten würde.
In der Liste haben wir eine Spalte ausgelassen, jedoch wird für die Modelle der R-Serie vor allem die Eyefinity-Technologie ein entscheidender Faktor sein. Die APUs verfügen über vier unabhängige Display-Controller, die gleichzeitig vier Ausgänge ansteuern können. Es sind vorhanden: 4x Single-Link-DVI (max. 1920x1080), 4x DisplayPort 1.2 (max. 4096x2160), 1x HDMI (max. 1920x1200) und VGA. Mithilfe von Adaptern dürfte wohl für jeden etwas dabei sein. Vor allem wenn wir an Video-Tafeln denken, so wäre die R-Serie dafür prädestiniert und muss nicht auf zusätzliche Hardware zurückgreifen.
Neben den vielfältigen visuellen Möglichkeiten bieten die AMD R-Serie-APUs laut Herstellerangabe aber auch vielfältige Möglichkeiten im Hinblick die Verschlüsselung von Datenströmen. Weiterhin biete man dem Kunden weitreichende Remote-Management-Funktionen.
Kombiniert werden die neuen R-Serie-APUs mit den bekannten Fusion Controller Hubs (FCH) A70M und A75. Die von den Desktop-Produkten bekannte A75 unterscheidet sich durch PCI-Ports, den RAID-10-Modus und dem FIS-based Switching von der Mobil-Variante. Die Leistungsaufnahme des A70M hängt von der Konfiguration ab, während AMD beim A75 einen Wert von 7,8 Watt angibt.
Vor einiger Zeit sollte der Online-Spiele-Dienst OnLive für eine Revolution auf dem Markt sorgen. Viel hört man aktuell von dieser Technik nicht mehr, vielleicht auch weil der Dienst in Deutschland noch nicht den Durchbruch hatte/hat. Bei einer Präsentation stellte NVIDIA seine neue GRID-Technologie vor. Laut eigenen Angaben habe man fünf Jahre an der Entwicklung der Technik gearbeitet, die zukünftig die Qualität dieser Dienste maßgeblich verbessern soll. Niedrigere Latenzen, höhere Bildqualität, effizientere Hardware seien demnach das Ergebnis dieser Arbeit. In einer Telefonkonferenz hat uns NVIDIA die Technik erklärt und im Folgenden wollen wir euch anhand der dort gewonnen Informationen die Technik etwas näher bringen.
NVIDIA GeForce GRID soll vor allem Nutzer ansprechen, die zwar auf ihren Geräten Online-Applikationen ohne Probleme ausführen können, jedoch nicht über die Rechenleistung verfügen, um grafisch aufwändige Inhalte wiederzugeben. In diese Kategorie von Endgeräten fallen inzwischen vielfältige Varianten: Tablets, Smartphones, Smart-TVs oder auch Set-Top-Boxen. GeForce GRID würde also folglich ermöglichen, Spiele überall nutzen zu können. Einzige Prämisse ist natürlich in diesem Fall noch, dass die Eingabemöglichkeiten geeignet sind. Daran arbeitet NVIDIA aber ebenfalls schon. Während dieser Punkt bei Tablets und Smartphones weniger schwerwiegend ist, weil die Touchscreens via Multitouch-Technik virtuelle Controller unterstützen, sind auch Hybrid-Geräte verfügbar, siehe Sony Ericcsons Xperia PLAY. Dort hat man in Anlehnung an das Layout der bekannten PlayStation-Controller aus einem Smartphone eine interessante mobile Alternative geschaffen. Doch zurück zum eigentlichen Thema.
Die große Frage, die sich wohl jeder stellt: Wie spielt man auf einem Gerät, wenn das Spiel nicht darauf installiert ist bzw. wie kommt das Bild auf den Bildschirm? Das Spiel wird auf dem Server im Rechenzentrum ausgeführt. Die neue GeForce-GRID-Hardware übernimmt die Berechnungen der Engine, sprich die Bilderstellung, encodiert diese im nächsten Schritt durch die Hardware und überträgt diese, ähnlich wie bei der Wiedergabe eines YouTube-Videos, auf die entsprechenden Endgeräte. Dort müssen die Bilder dann nur noch decodiert und abgebildet werden. Auf die Wiedergabe auf den Endgeräten kann der Hersteller nun nicht viel Einfluss nehmen, da die Hardware-Ausstattung von Gerät zu Gerät variiert, aber im Allgemeinen sind alle Geräte geeignet, die flüssige Bildraten bieten.
NVIDIA setzt bei GeForce GRID bei den Servern an, auch wenn sich netztechnisch einiges getan haben soll. In Kooperation mit den Providern soll die Netzqualität, in diesem Fall die Latenz zwischen Server und Endgerät, reduziert worden sein.
Laut NVIDIA kam schon im Falle des On-Live-Dienstes, also der ersten Generation cloud-basierten Rendering, NVIDIA-Hardware zum Einsatz. Die erste GeForce GRID, sprich die Hardware hinter dem Namen, setzt auf zwei GPUs. Dabei handelt es sich um zwei GK104-GPUs, wie sie auch bei den aktuellen Grafikbeschleunigern GeForce GTX 680 und GTX 690 zum Einsatz kommt. Über die Taktrate für die insgesamt 3072 Streamprozessoren macht NVIDIA keine offizielle Angabe. Im Normalfall liegen die Taktraten im professionellen Umfeld etwas niedriger als im Consumer-Segment. Stabilität ist hierbei wichtiger als die reine Leistung. Dafür muss man einen Punkt vor allem erwähnen. Die neuen GeForce GRID sind wie ihre Desktop-Pendants nicht für Double-Precision-Berechnungen geeignet. Das bedeutet, dass sie sich nicht für wissenschaftliche Zwecke eignen. Aufgrund der Bestimmung als Spiele-Hardware dürfte dies aber nur wenig interessieren.
Wie aus dem Server-Bereich gewohnt, beherrschen die GeForce GRID Virtualisierungstechniken. Während diese Technik bisher eher für Prozessoren gültig war, können nun mehrere Spiele-Sessions auf einer Grafikkarte ausgeführt werden. Aktuell gibt NVIDIA an, dass zwei Spiele pro Grafikkern aktiv sein können. Die Auflösung beträgt dabei 1280x720 bei 30 Bildern pro Sekunde. Die Qualität der Bilder soll mit der auf einem Heim-PC vergleichbar sein. Mit reduzierten Details soll es auch möglich sein, noch mehr aus der Hardware herauszuholen. Bis zu sechs Streams seien im Rahmen des Möglichen, dabei muss man aber wahrscheinlich auf Details verzichten oder die Auflösung reduzieren. 1920x1080 Bildpunkte bei 60 Bildern pro Sekunde können ebenfalls dargestellt werden. Man muss dabei aber immer wieder im Hinterkopf behalten, dass die Bandbreite des Nutzers ebenso entscheidend ist. Wie man auch bei YouTube am heimischen PC sieht, müssen die Bilder auch dorthin gelangen können. Aufgrund der Bandbreitenproblematik geht NVIDIA von den 1280x720 in der Regel aus.
Das Encodieren der einzelnen Streams sei kein Problem. Der integrierte Hardware-Encoder kann mit multiplen Streams umgehen, wobei man bedenken muss, dass NVIDIA durch seine Quadro-Grafikkartenserie wohl schon einige Erfahrung in diesem Bereich mitbringen dürfte.
Wir haben weiter oben schon davon gesprochen, dass die Steuerung für die Spiele auf die Endgeräte angepasst werden muss. Die Umsetzung ist laut NVIDIA weniger das Problem und bedarf relativ wenig Zeit. Aktuelle Spiele sollen stets mit ins Programm aufgenommen werden. Trotzdem wird in diesem Zusammenhang auch die Frage laut, ob wir eventuell auch in Zukunft Spiele sehen werden, die exklusiv für GeForce GRID erscheinen. Bis jetzt soll so etwas aber noch nicht geplant sein, sodass der Unterschied zwischen Heim-PC und Online-Dienst nicht zu groß ausfällt. Weiterhin wird es so sein, dass sich die Spiele-Programmierer momentan eher auf die bestehenden Zugpferde PC, Sony PlayStation und Microsoft XBOX 360 stützen werden, da diese einen Großteil des Marktes ausmachen, in den die Cloud-Gaming-Anbieter erst noch drängen wollen.
Dabei fällt auch auf, dass es die beschriebene Technik noch nicht wirklich auf den deutschen Markt geschafft hat. Laut unseren (zugegeben kurzen) Recherchen ist es aktuell nur mit Tricks möglich, Dienste wie OnLive zu nutzen. NVIDIA führt Namen wie Gaikai, ubitus, otoy, Playcast und G-Cluster an, wobei nur die beiden letztgenannten für den europäischen Markt aktuell tätig sein sollen. Playcast betreut wohl speziell Frankreich momentan. Ob wir also in naher Zukunft in unserem Land von GeForce GRID profitieren können, ist fraglich. Ebenso dürften die stark schwankenden Netzqualitäten deutscher Provider immer wieder dafür sorgen, dass sich in diesem Bereich Ärger ankündigt. Pingschwankungen, wie sie öfter einmal auftreten können, würden immer wieder für ein ruckeliges Spielgefühl sorgen.
Neben den Vorteilen für die Privatkunden führt NVIDIA aber auch Argumente für die Betreiber solcher Dienste ins Feld. GeForce GRID sei demnach günstiger als die erste Generation, biete eine höhere Qualität und ermöglicht bessere Latenzen. Bei den Kosten spielt wohl vor allem die Energieeffizienz eine Rolle. Demnach halbiert sich die Leistungsaufnahme pro Spiele-Stream von 150 auf 75 Watt. Ebenso erhöht die Dual-GPU-Bauweise die Packungsdichte im Rack. Mehr Power bei weniger Platzbedarf.
Man kann gespannt sein, ob sich die Technik irgendwann durchsetzen kann. Trotz der bisher eher schlechten Bewertungen der Dienste scheint das Thema Cloud-Gaming für die Hersteller immer noch ein heißes Eisen zu sein, wie NVIDIA nun mit GeForce GRID beweist.
be quiet! ist ohne Zweifel die stärkste A-Marke in Deutschland und erweitert seine Serien regelmäßig, um die Lautstärke und den Wirkungsgrad zu verbessern. Aus der Mitte des Portfolios haben wir uns das Straight Power E9 CM mit 580 W herausgegriffen und bewerten die Entwicklung der Marke anhand dieses typischen Produkts. Die Straight-Power-Serie bildet den Mainstream zwischen den günstigen Pure Power und den etwas teureren Dark Power Pro. Zu letzteren allerdings wird der Abstand immer kleiner, da viele Modelle der aktuellen Mittelklasse bereits über abnehmbare Anschlüsse verfügen. Dazu zählt auch das Modell, welches sich heute beweisen muss. Auf den folgenden Seiten werden wir näher darauf eingehen, ob be quiet! seinem Namen gerecht wird. Wir wünschen viel Spaß beim Lesen und noch einen schönen Feiertag!
Einige haben die entsprechenden Logos vielleicht auch schon in den Folien von AMD entdeckt, denn es gab auf dem Presse-Event zur Vorstellung von AMDs zweiter Generation A-Serie APUs (Codename "Trinity") eine Überraschung: Der plattformübergreifende Open-Source-Encoder x264 für das Video-Format H.264 (MPEG-4 AVC) und damit auch das Videotool HandBrake, welches eine grafische Benutzeroberfläche für eben diesen Encoder ist, werden per OpenCL beschleunigt. Leider hielten sich die Sprecher von AMD uns gegenüber zu den Details der Umsetzung trotz mehrfacher Nachfragen bedeckt. Glücklicherweise bringen die Kollegen von AnandTech jetzt Licht ins Dunkel, immerhin handelt es sich hier um Tools, welche sich einer deutlich größeren Beliebtheit erfreuen dürften, als die meisten kommerziellen H.264-Kodierer. Das liegt neben dem offensichtlichen Grund (beide sind kostenlos verfügbar) an der sehr guten Bildqualität kombiniert mit einer sehr effizienten Kompression und Ausnutzung von Mehrkernprozessoren.
Laut AnandTech verfolgen die Entwickler von HandBrake bei der GPU-Beschleunigung mehrere Ansätze: Zum einen verwendet das Transkodierungs-Tool die DXVA-Schnittstelle von Microsoft Windows, um die Dekodierung des Ausgangsformates über die GPU zu beschleunigen. Dabei kommt entsprechend der jeweiligen Hardware ein spezieller, festverdrahteter Funktionsblock (z. B. UVD von AMD oder PureVideo HD von NVIDIA) zum Einsatz, welcher speziell für diese Aufgabe optimiert wurde. Zum anderen werden GPU-typische Aufgaben wie die Skalierung und Farbraumkonvertierung ebenfalls auf die GPU ausgelagert. Außerdem soll für die Berechnung der "Lookahead"-Funktion des Enkodierungsprozesses ebenfalls über OpenCL auf die GPU zurückgegriffen werden. Diese Teilaufgabe ist hierfür gut geeignet, weil es sich um ein datenparalleles Problem handelt, welches bereits in einem eigenen Thread läuft. Mit der "Lookahead"-Funktion bestimmt der Encoder, wie viele Frames er vorausschauen muss, um eine optimale Bildqualität zu erreichen. Dies ist wichtig, da die Komprimierungsalgorithmen im wesentlichen darauf aufbauen, dass lediglich die Änderungen zwischen den einzelnen Bildern gespeichert werden. Letztlich ist es also das Ziel, die redundanten Daten so stark wie möglich zu reduzieren.
Für einen ersten Test stand AnandTech eine frühe Entwicklerversion von HandBrake sowie die aktuelle stabile Version des Tools zur Verfügung. Als Ausgangsmaterial für den Vergleich nutzten die Kollegen ein 1080p-Video im MPEG-2-Format, welches in das Formal H.264 mit einer Auflösung von 720p transkodiert wurde. Hierzu kam das High Profile von Handbrake mit den Standardeinstellungen zum Einsatz. Alle für den Test herangezogenen AMD- und Intel-Prozessoren erreicht mit der GPU-beschleunigten Version höhere FPS-Werte. Die getestete AMD A8-3500M APU ("Llano") verbesserte sich von 5,7 FPS auf 12,05 FPS und die AMD A10-4600M APU ("Trinity") von 6,98 FPS auf 15,01 FPS, was in beiden Fällen einer Verdoppelung der Trankodierungsleistung entspricht. Damit kann die "Trinity"-APU den Rückstand auf den Intel i7-2820QM ("Sandy Bridge") von enormen 73% auf lediglich 7% stark verkürzen, der allerdings mangels OpenCL-Unterstützung lediglich von der GPU-beschleunigten Dekodierung profitieren kann. Der Intel i7-3720QM ("Ivy Bridge") hält hingegen die Konkurrenz auch mit Beschleunigung auf Abstand.
Was dieser erfreuliche "OpenCL-Boost" für HandBrake bzw. x264 wirklich Wert ist, muss sich noch zeigen. Bisher konnten GPU-beschleunigte Encoder zwar zumeist überzeugen, wenn es allein um die Geschwindigkeit ging, lieferten dabei aber eine indiskutable Bildqualität ab. Letztlich lautete daher die Empfehlung, lieber die deutlich längere Rechenzeit auf der CPU in Kauf zu nehmen. Es bleibt zu hoffen, dass die Implementierung von x264 es besser macht. AnandTech trifft hierzu leider nur die Aussage, dass sie keinen Qualitätsunterschied zwischen den unterschiedlichen Ausgaben beobachten konnten, die mittels der OpenCL-beschleunigten Transkodierung erstellt wurden. Zudem wiesen die transkodierten Videodateien, welche allein auf den CPU-Kernen berechnet wurden, höhere Datenraten auf - wurden also weniger stark komprimiert. Diese Unterschiede können dem frühen Entwicklungsstadium der GPU-Beschleunigung geschuldet sein.
Der Projektleiter von x264, Jason Garrett-Glaser kommentierte die Zusammenarbeit mit AMD wie folgt:
Zitat:
"x264 is the world's leading video encoding library, used in applications ranging from web video to broadcast television, cloud gaming, telemedicine, Blu-ray, and more. AMD has been a great partner, working openly as part of the open source community to help enhance x264 with GPU capabilities using OpenCL."
Wann die GPU-beschleunigten Versionen von h264 und HandBrake verfügbar werden, ist unbekannt. Dies liegt aber in der Natur von Open-Source-Projekten, schließlich hängt das Tempo entscheidend davon ab, wie viel Zeit die freiwilligen Entwickler aufbringen können.
Anand Lal Shimpi und Jarred Walton haben in den Kommentaren zur News bei AnandTech weitere Details zum Stand der Implementierung verraten. Offenbar wird der OpenCL-Code derzeit nicht vom x264-Projekt entwickelt, sondern von AMD intern. Irgendwann soll der Code und die zugehörige Dokumentation dann der Open-Source-Community zugänglich gemacht werden. Derzeit befindet er sich unter Verschluss und kann ausschließlich von AMD direkt bezogen werden. Zudem hat sich AMD wohl bisher auf die Optimierungen für integrierte Grafiklösungen konzentriert, weshalb AnandTech darum gebeten wurde, vorerst keine Tests auf diskreten Grafiklösungen durchzuführen.
Zitat: Jarred Walton
"The OpenCL code at present is developed in house by AMD and they will eventually provide all of the code and documentation back to the open source community. However, for now it is all under tight wraps and there is no way to get it (other than from AMD)."
Zitat: Anand Lal Shimpi
"Not quite yet, the current build hasn't really been optimized or tested for dGPU usage. We were asked to limit our testing to integrated solutions for the time being."
Zum Launch der ersten APUs von AMD wurde immer wieder hinterfragt, warum der GPU-Teil keine Unterstützung für Berechnungen mit doppelter Genauigkeit bietet. Schließlich preist das Unternehmen seine Accelerated Processing Units (APUs) damit an, dass der auf dem Die verbaute "Discrete Class" Grafikkern auch für andere Berechnungen (GPGPU-Computing) als das reine Redering von Computerspielen herangezogen werden kann. Während es im normalen Endkundenmarkt durchaus verschmerzbar ist, dass Berechnungen mit doppelter Genauigkeit nicht auf dem GPU-Teil der APU ausgeführt werden können, so ist es für wissenschaftliche Anwendungen fast schon Pflicht. Zwar existieren dort noch andere Anforderungen, die von den aktuellen APUs nicht erfüllt werden (z. B. ECC), allerdings wird beispielsweise bereits ein Supercomputer auf APU-Basis für Forschungszwecke auf dem Gebiet des "Heterogeneous Computing" genutzt. Zudem würden sich die Entwickler sicherlich freuen, wenn sie ihre Codes bereits auf ihrem Notebook oder Desktop-Rechner testen könnten und AMD allgemein beim Funktionsumfang eine konsistente Plattform bereitstellt. Dazu zählt eben auch, dass alle GPUs für Berechnungen mit doppelter Genauigkeit herangezogen werden können. Einen ersten Schritt dahingehend hat das Unternehmen mit der neuen GCN-Architektur getan, denn alle darauf basierenden GPUs unterstützen Double Precision (DP).
Entsprechend dieser Folien ist der Grafikteil von "Trinity" jetzt also auch dazu in der Lage, Berechnungen mit doppelter Genauigkeit auszuführen, wenn auch lediglich mit 1/16 der Rechenleistung, die für einfache Genauigkeit (Single Precision) erreicht wird. Damit liegt die theoretische DP-Peak-Leistung der GPU von 24 GFLOPs unterhalb der mit den FPUs der CPU-Kerne erreichbaren 37 GFLOPs. Damit ist die Auslagerung von DP-Berechnungen auf den Grafikkern der APU in den meisten Fällen wohl nicht sinnvoll. AnandTech konnte dies auch anhand der Ausgabe von clinfo bestätigen (siehe Artikel-Kommentare).
Im Rahmen der Vorstellung von AMDs zweiter Generation A-Serie-APUs sind auch erste offizielle Details zu "Brazos 2.0" bekannt gegeben worden. Auch wenn die Versionsnummer 2.0 größere Änderungen vermuten lässt, so handelt es sich im Wesentlichen doch nur um einen zweiten Refresh zur Produktpflege der altbekannten "Brazos"-Plattform. Damit soll die Streichung des ursprünglich geplanten Nachfolgers, für den eine Fertigung im 28nm-Prozess geplant war, kaschiert werden. Ein leichtes Erbe tritt "Brazos 2.0" jedenfalls nicht an, schließlich bezeichnet das Unternehmen "Brazos" als das erfolgreichste Produkt der Unternehmensgeschichte. Allein 2011 konnten 30 Mio. Stück der kleinen C- und E-Serie APUs (Accelerated Processing Unit) abgesetzt werden.
Welche Verbesserungen und Optimierungen hat also "Brazos 2.0" zu bieten? Neben leicht höheren Taktraten für die CPU- (+50 MHz) und GPU-Kerne (+25 bzw. +80 MHz) auf dem "Ontario"-Die hat AMD in erster Linie am Unterbau geschraubt. Dank des von der "Sabine"-Notebookplattform entliehenen neuen Chipsatzes (AMD A68M FCH) stehen jetzt auch die neuen Schnittstellen USB 3.0 und SATA 6Gb/s zur Verfügung. Darüber hinaus können die OEMs auf den integrierten Controller für SD-Speicherkartenlesegeräte zurückgreifen. Abschließend wollen die Entwickler die Leistungsaufnahme des Fusion Controller Hub (FCH) weiter reduziert haben. Dies und weitere Optimierungen an der Plattform sollen zu einer längeren Akkulaufzeit beitragen.
Als zusätzliche neue Features nennt AMD Steady Video 1.5 und eine Quick Stream getaufte Technologie. Bei ersterem handelt es sich um ein bereits von den A-Serie APUs bekanntes Feature zur Stabilisierung verwackelter Videoaufnahmen in Echtzeit. Inwiefern die kleinen APUs überhaupt dazu in der Lage sind, die benötigte Rechenleistung zu erbringen, muss sich noch zeigen. Es ist anzunehmen, dass der Filter lediglich bei kleineren Auflösungen sinnvoll zuschaltbar sein wird. Quick Stream soll dafür sorgen, dass Video-Streams bei der Verteilung der Netzwerkbandbreite priorisiert werden. Damit soll eine unterbrechungsfreie Betrachtung von Internetvideos ermöglicht werden, wobei allerdings die OEMs entscheiden, ob diese Technologie im jeweiligen Produkt enthalten ist.
Zu den konkreten Produkten von "Brazos 2.0" schweigt sich AMD zwar noch aus, dennoch haben wir auf Basis aktueller Spekulationen die wahrscheinlichen technischen Daten der beiden neuen APUs in die nachfolgende Tabelle eingetragen.
Technische Daten der neuen Modelle auf Basis aktueller Spekulation ergänzt (Quelle:Computer Base)
Einen genaueren Termin für den Start von "Brazos 2.0" nennt AMD derzeit nicht, stattdessen wird lediglich die Verfügbarkeit entsprechender Produkte recht vage für das zweiten Halbjahr 2012 angekündigt, sodass der Start mit den üblichen Marktzyklen zusammenfallen soll. Spätestens zum Launch von Windows 8 sollten entsprechende Geräte den Weg in die Verkaufsregale gefunden haben.
Nachdem heute Nacht um 2 Uhr bereits das dritte Projekt beim diesjährigen BOINC-Pentathlon zu Ende gegangen ist, biegt der "moderne Fünfkampf" auf die Zielgerade ein. Unser Team von Planet 3DNow! konnte sich zum Auftakt mit einem souveränen Start-Ziel-Sieg den ersten Platz in der Teildisziplin Biologie & Medizin sichern und zudem die Silbermedaille in der GPU-Disziplin Collatz Conjecture erringen. Beim darauf folgenden dritten Projekt World Community Grid (Showbag) gab es dann mit Platz sechs einen kleinen Durchhänger, schließlich galt es, den abschließenden Wettkampf um den Gesamtsieg vorzubereiten. Immerhin werden bis zum Finale am 19. Mai um 1:59 Uhr die beiden CPU-Projekte yoyo@home (Mathematik) und QMC@HOME (Physik & Chemie) parallel gerechnet. Entsprechend ordentlich ist das Team auch in beiden Disziplinen aus den Startblöcken gekommen, sodass aktuell sogar jeweils der erste Platz gehalten werden kann. Damit liegen wir aktuell auch in der Gesamtwertung auf dem ersten Platz, den es nun mit aller Macht zu verteidigen gilt. Die Goldmedaille in der Kategorie Biologie & Medizin sowie die erste Medaille in einem GPU-Projekt kann uns aber keiner mehr nehmen.
Aktuell liegt Planet 3DNow! in beiden abschließenden Disziplinen sehr gut im Rennen, was aber in erster Linie dem geschickten Aufbau von großen "Bunkern" in beiden Projekten zu verdanken ist. Um diese "Bunker" aufzubauen, wurden bereits vor dem eigentlichen Startschuss Work-Units (WUs) auf Halde gerechnet. Somit konnten auf einen Schlag extrem viele fertige WUs abgeliefert und die entsprechenden Punkte kassiert werden. Natürlich hatten auch die anderen Teams auf Halde gerechnet, sodass es gerade in den ersten Stunden nach dem Start der abschließenden Projekte zu stetigen Platzwechseln kam. Jetzt gilt es, die ersten Plätze bei yoyo@home und QMC@HOME mit möglichst hoher Dauerrechenleistung zu halten und nach Möglichkeiten den Vorsprung weiter auszubauen, denn noch haben nicht alle Teams ihre Karten auf den Tisch gelegt. Die engsten Verfolger in der Gesamtwertung SETI.Germany und SETI.USA haben sicherlich noch den einen oder anderen Pfeil im Köcher. Wer also noch freie Rechenkapazitäten hat, ist herzlich dazu eingeladen, unser Team zu unterstützen. Jeder CPU-Kern zählt! Schnelle Hilfe finden Interessierte im Pentathlon-Thread.
Für Einsteiger empfiehlt es sich den Sammelthread mit einigen Hilfestellungen zu lesen, oder sich vertrauensvoll per PM an Opteron zu wenden, der einen "Rundum-Sorglos Account" managt. Eine kleine Übersicht hat zudem unser User Nightshift erstellt. Sollten dennoch Fragen offen bleiben, steht das Team im Pentathlon-Thread mit Rat und Tat zur Seite.
Bleibt nur noch zu sagen: "Wir brauchen mehr POWER!"
AMDs Trinity, wie er heute vorgestellt wird, soll wie schon der Vorgänger kein Hitzkopf sein. Die grüne Prozessorschmiede streicht sogar die 45-W-TDP-Klasse und fügt stattdessen eine neue mit nur 17 W zum Portfolio hinzu, obwohl die Transistoranzahl und die Die-Fläche gestiegen sind. Neu sind außerdem die Unterstützung für Eyefinity zum Ansteuern von mehr als zwei Monitoren und AMDs Turbo Core 3. Der Anwender wird im Taskmanager aber wie bisher maximal vier Threads erblicken. Dabei handelt es sich aber nicht wie bisher um vier eigenständiger Kerne, sondern zwei Module, wie wir sie bereits von Bulldozer-CPUs her kennen. AMD hat sich aber hingesetzt und die Module überarbeitet, herausgekommen sind sogenannte Piledriver-Kerne. Allzu viele Neuerungen sollten hier allerdings nicht erwartet werden. Es wurde vermutlich eher mehr Feintuning betrieben, um einige Flaschenhälse der Architektur abzumildern oder gar zu beseitigen, dazu mehr auf den nächsten Seiten.
So langsam veröffentlichen die Hersteller die Produkte, die man bereits dieses Jahr auf der CeBIT zu sehen bekam. Gestern schickte bereits Xilence die neue XQ-Serie ins Rennen. Bei SilverStone gibt es Neuigkeiten aus der Fortress-Gehäuseserie. Das bekannte FT03 wird im Prinzip geschrumpft, das Ergebnis ist das FT03-Mini. 50 % kleiner soll es sein als das große Modell und den mITX-Sektor stärken. Wie beim Scythe Katana 4 kürzlich, haben wir das Modell auf der Messe fotografiert, aber nicht genau hingeschaut. Das hat aber auch einen Vorteil: Wir können euch auch Impressionen vermitteln.
Das SilverStone Fortress FT03-Mini wird laut Herstellerangaben in den Farben Schwarz und Silber erhältlich sein und aus 2,5 mm starkem Aluminium gefertigt. Die Oberfläche wird bei einem Sandstrahlvorgang aufgewertet. Gegenüber gebürstetem Aluminium hat sich in unseren Augen diese Methode als praktischer herausgestellt. Die man auf unserem Foto von der CeBIT sehen kann, sind Fingerabdrücke zwar leicht sichtbar, fallen aber nicht allzu sehr auf.
Während die Sugo-Modelle SilverStones das Mainboard in liegender Position aufnehmen, wird beim FT03-Mini gleich zweimal gedreht. Ein mITX-Mainboard wird nicht nur aufrecht wie von Towern gewohnt verbaut, sondern zusätzlich noch mit der Backplate nach oben. Von dieser Maßnahme erhofft sich der Hersteller, den natürlichen Kamineffekt auszunutzen. Die warme Luft steigt nach oben und verlässt das Gehäuse. An der Oberseite besitzt das FT03-Mini über ein großmaschiges Gitter. Dieses dient nicht nur der Entlüftung, sondern verdeckt auch die darunter liegenden Anschlusskabel.
Für die aktive Belüftung verwendet SilverStone einen 140-mm-Lüfter aus dem eigenen Programm, einen Air Penetrator. Wenn wir an die Kühlung der verbauten Hardware denken, gibt der Hersteller an, dass für einen CPU-Kühler maximal 78 mm in der Höhe zur Verfügung stehen. Trotz der Verwendung des mITX-Standards soll es möglich sein, einfach Wasserkühlungen zu verwenden. Was das im Detail bedeutet, können wir euch leider nicht sagen. Wir gehen aber davon aus, dass SilverStone damit Fertig-Wasserkühlung wie Antecs H20-Serie oder auch Corsairs H-Serie meint. Erweiterungskarten sollen höchstens 254 mm messen. Bei der Netzteilwahl ist man etwas eingeschränkt. Während Konkurrent Lian Li beispielsweise immer wieder dem ATX-Standard folgt, setzt SilverStone ein SFX-Netzteil voraus, das sich nicht im Lieferumfang befindet.
Bei der Laufwerksauswahl wird ebenso ein wenig eingeschränkt. Als optisches Laufwerk kommt nur ein 5,25"-Modell im Slim-Format in Frage, das per Slot-In gefüttert wird. Bei den Festplatten dominieren die 2,5"-Laufwerke. Zwei Stück können verbaut werden, sodass die Kombination aus HDD und SSD möglich wird. Hinzu kommt ein Montageplatz für eine 3,5"-Festplatte.
Die Verfügbarkeit gibt der Hersteller mit dem morgigen Datum, dem 16.05.2012 an. Die unverbindliche Preisempfehlung beträgt ungefähr 106,90 Euro ohne Mehrwertsteuer (ca. 127 Euro mit Mwst.). Im Preisvergleich können wir das Gehäuse noch nicht finden.
Bereits auf der CeBIT 2012 führte Xilence die neuen Netzteile der XQ-Serie vor. Zu dieser Zeit handelte es sich noch um Vorab-Versionen, an denen man uns die Technik erklärte. Die äußere Form des Netzteils unterscheidet sich vom bekannten Design anderer Hersteller. Dank semi-passiver Belüftung durch zwei getrennt gesteuerte 60-mm-Lüfter soll es dank hoher Effizienz gute Werte bei der Lautstärke erreichen. Ab heute sollen die beiden 80Plus-Gold zertifizierten Netzteile mit 750 und 850 Watt erhältlich sein. Gegen Ende des Monats wird laut Herstellerangaben auch das 1000 Watt Platinum-Modell folgen. Neben der bereits beschriebenen Direct-Airflow-Technologie mit getrennt geregelten Lüftern, die erst ab einer Belastung von 20 bis 30 % aktiv werden sollen, ist wohl die SMD-Technologie zur Bestückung des PCB zu erwähnen. Durch diese steigt die Qualität der Lötstellen im Normalfall an. Aufgrund der potenziell hohen Verarbeitungsqualität gewährt Xilence bis zu 5 Jahre Garantie auf die XQ-Netzteile. Um die maximale Garantiedauer zu erhalten, ist eine Online-Registrierung beim Hersteller erforderlich. Im ersten Jahr ist laut Herstellerangaben auch ein Vor-Ort-Austausch im Garantiefall vorgesehen.
Weitere Informationen zur Technik, wie etwa die Leistungsdaten, und auch Bildmaterial findet ihr in unserer News von der CeBIT 2012.
Dass das Ganze einen etwas höheren Preis nach sich zieht, war schon bei der CeBIT klar. Die unverbindliche Preisempfehlung für die beiden neuen Modelle beträgt 179 Euro (750 Watt) respektive 189 Euro (850 Watt). Bei den Händlern liegen wir bereits heute ungefähr 5 Euro unter dieser Angabe.
AMDs APUs der A-Serie sind nun schon fast ein Jahr auf dem Markt. Zur Markteinführung kämpfte man stark damit, die Anfragen abarbeiten zu können. Im Laufe der Zeit verbesserte sich nicht nur die Verfügbarkeit, es kamen auch kleinere Modelle auf den Markt sowie ein günstigerer Fusion Controller Hub (FCH), wie der Chipsatz sich in diesem Fall nennt. Der A55-Chipsatz verzichtet sowohl auf USB 3.0 als auch den neuesten SATA-Standard mit einer Bandbreite von 6 Gbit/s. Alles zu Gunsten eines attraktiveren Einstiegspreises. Wir wollen in diesem Artikel also nicht nur die reine Leistung einer kleinen APU beurteilen, sondern auch der Frage nachgehen, ob es der A75-Fusion-Controller-Hub sein muss oder nicht doch die günstige Variante ausreichend ist.
Heute Nacht um 2 Uhr endete die erste Disziplin Rosetta@home im "modernen Fünfkampf". Unser Team konnte sich in dieser ersten Teildisziplin zum Auftakt mit einem souveränen Start-Ziel-Sieg den ersten Platz sichern und sich damit gegenüber dem Vorjahr steigern, als wir "nur" die Silbermedaille erringen konnten. Nach diesem Auftakt nach Maß gilt es allerdings alle Kräfte auf die aktuell parallel laufenden Projekte Collatz Conjecture und World Community Grid - einer Sammlung verschiedener Forschungs-Projekte - zu bündeln. Zwar liegen wir aktuell bei ersterem auf einem guten zweiten Platz, allerdings steht das Team bei letzterem Projekt derzeit stark unter Druck, wodurch wir in der Gesamtwertung vom ersten auf den dritten Platz zurückgefallen sind. Die Goldmedaille in der Kategorie Biologie & Medizin kann uns aber nicht mehr genommen werden.
Offenbar haben die anderen Teams Rosetta@home schnell abgehakt und sich stattdessen auf die anderen Projekte konzentriert. Besonders das Team SETI.Germany hat wohl frühzeitig angefangen einen großen Bunker aufzubauen, d. h. es hat bereits vor dem eigentlichen Startschuss auf Halde gerechnet und konnte somit auf einen Schlag einen Berg fertiger Workunits (WUs) anrechnen lassen. Dadurch ist es aktuell auf dem zweiten Rang hinter dem - quasi außer Konkurrenz rechnenden - Team 2CH, gefolgt von SETI.USA, Team China und L'Alliance Francophone. Planet 3DNow! steht aktuell auf dem sechsten Platz. Wer also noch freie Rechenkapazitäten hat, ist herzlich dazu eingeladen, unser Team zu unterstützen. Jeder CPU-Kern zählt! Auch bei Collatz Conjecture können wir jede Hilfe gebrauchen, hier ist Grafikkarten-Power gefragt. Vorgestern konnten wir zwar SETI.Germany überholen, allerdings gilt es den zweiten Platz abzusichern und vielleicht geht ja auch noch was nach oben. Schnelle Hilfe finden Interessierte im Pentathlon-Thread.
Wir haben es erst jetzt erfahren, wollen es aber unbedingt erwähnen: Das Team l'Alliance Francophone betrauert den Tod seines langjährigen Team-Mitgliedes Jip und widmet ihm daher den diesjährigen BOINC-Pentathlon. Unser Beileid und Mitgefühl gilt seiner Familie und seinen Freunden!
Für Einsteiger empfiehlt es sich den Sammelthread mit einigen Hilfestellungen zu lesen. Eine kleine Übersicht hat zudem unser User Nightshift erstellt. Sollten dennoch Fragen offen bleiben, steht das Team im Pentathlon-Thread mit Rat und Tat zur Seite.
Bleibt nur noch zu sagen: "Wir brauchen mehr POWER!"
Zum Patchday hat Microsoft heute sieben Sicherheitsmitteilungen veröffentlicht.
Die Sicherheitsmitteilungen im Detail:
MS12-029 - Sicherheitsanfälligkeit in Microsoft Word (KB2680352) Art der Lücke: Remotecodeausführung Betroffene Software: Office 2003, 2007, 2008 for Mac, 2011 for Mac, Office Compatibility Pack Maximaler Schweregrad: Kritisch Neustart erforderlich: Möglicherweise Update-Empfehlung: Sofortige Installation
MS12-030 - Sicherheitsanfälligkeiten in Microsoft Office (KB2663830) Art der Lücke: Remotecodeausführung Betroffene Software: Office 2003, 2007, 2008 for Mac, 2010, 2010 x64, 2011 for Mac, Excel Viewer, Office Compatibility Pack Maximaler Schweregrad: Hoch Neustart erforderlich: Möglicherweise Update-Empfehlung: Schnellstmögliche Installation
MS12-031 - Sicherheitsanfälligkeit in Microsoft Visio Viewer 2010 (KB2597981) Art der Lücke: Remotecodeausführung Betroffene Software: Visio Viewer 2010, 2010 x64 Maximaler Schweregrad: Hoch Neustart erforderlich: Möglicherweise Update-Empfehlung: Schnellstmögliche Installation
MS12-032 - Sicherheitsanfälligkeit in TCP/IP (KB2688338) Art der Lücke: Erhöhung von Berechtigungen Betroffene Software: Windows Vista, Vista x64, 2008, 2008 x64, 2008 IA64, 7, 7 x64, 2008 R2 x64, 2008 R2 IA64 Maximaler Schweregrad: Hoch Neustart erforderlich: Ja Update-Empfehlung: Schnellstmögliche Installation
MS12-033 - Sicherheitsanfälligkeit im Windows Partitions-Manager (KB2690533) Art der Lücke: Erhöhung von Berechtigungen Betroffene Software: Windows Vista, Vista x64, 2008, 2008 x64, 2008 IA64, 7, 7 x64, 2008 R2 x64, 2008 R2 IA64 Maximaler Schweregrad: Hoch Neustart erforderlich: Ja Update-Empfehlung: Schnellstmögliche Installation
MS12-034 - Kombiniertes Sicherheitsupdate für Microsoft Office, Windows, .NET Framework und Silverlight (KB2681578) Art der Lücke: Remotecodeausführung Betroffene Software: Windows XP, XP x64, 2003, 2003 x64, 2003 IA64, Vista, Vista x64, 2008, 2008 x64, 2008 IA64, 7, 7 x64, 2008 R2 x64, 2008 R2 IA64, Office 2003, 2007, 2010, 2010 x64, .NET Framework 3.0, 3.5.1, 4.0, Silverlight 4, 5 Maximaler Schweregrad: Kritisch Neustart erforderlich: Möglicherweise Update-Empfehlung: Sofortige Installation
Heute Nacht um 2 Uhr begann die Wertung des zweiten Projektes Collats Conjecture. Es versucht eine Lösung für das 1937 veröffentlichte Collatz-Problem zu finden. Wer dieses Projekt und noch vielmehr Planet 3DNow! beim diesjährigen Fünfkampf unterstützen will, ist herzlichst eingeladen.
Beim ersten Projekt hat sich einiges getan. Unser Team ist mit knappen Vorsprung noch immer auf dem ersten Rang bei Rosetta@home (Statistik). Beim heute Nacht begonnen zweiten Projekt belegt Planet 3DNow! einen guten dritten Platz (Statistik), obwohl uns GPU-Projekte wie dieses nicht so gut liegen. Die Berechnungen sollten hierbei ausschließlich auf der Grafikkarte ausgeführt werden. CPUs sind hier verhältnismäßig langsam. Als Resultat der beiden Wertungen stehen wir aktuell auf dem zweiten Platz in der Gesamtwertung.
Außerdem wurden heute morgen die zwei letzten Projekte bekannt gegeben. Nachdem also am Donnerstag World Community Grid startet, werden danach ab dem 14.05 für fünf Tage parallel yoyo@home und QMC@home gerechnet. Letzteres Projekt ist eines der "Heimprojekte" des grünen Planeten, so konnte unser Team schon im letzten Jahr hier den ersten Platz erreichen.
Für Einsteiger empfiehlt es sich den Sammelthread mit einigen Hilfestellungen zu lesen. Eine kleine Übersicht hat zudem unser User Nightshift erstellt. Bleibt nur noch zu sagen: "Wir brauchen mehr POWER!"
Heute Nacht um 2 Uhr begann die Wertung des Wettkampfes mit dem ersten Projekt: Rosetta@home. Dieses Wissenschaftliche Projekt hat es sich zur Aufgabe gemacht, Proteinstrukturen zu untersuchen um damit schwere Krankheiten zu verstehen und so die Voraussetzungen für bessere Behandlungsmethoden zu finden. Wer dieses Projekt und noch vielmehr Planet 3DNow! beim diesjährigen Fünfkampf unterstützen will, ist herzlichst eingeladen.
Nach einem grandiosen zweiten Platz im letzten Jahr, welchen unser Team vor allem durch viele herbeigeeilte Helfer erreichte, wird es diesmal vermutlich schwerer. Doch es sieht im frühen Stadium tatsächlich gut für uns aus! Aktuell belegen wir bei Rosetta@Home in der Pentathlonwertung Platz zwei. Aber es ist knapp, die ersten fünf Teams haben mit um die 500.000 Credits relativ ähnliche Punktezahlen. Vor uns steht das Team Meisterkühler.de auf dem ersten Rang. Hinter uns sammeln sich BOINCstats, Team 2CH und Seti.Germany.
Update 12:30: In der Zwischenzeit konnten wir den ersten Platz beim Projekt Rosetta@home ergattern. Damit steht unser Team das erste mal an vorderster Stelle der Gesamtwertung.
Für Einsteiger empfiehlt es sich den Sammelthread mit einigen Hilfestellungen zu lesen. Eine kleine Übersicht hat zudem unser User Nightshift erstellt.
Bleibt nur noch zu sagen: "Wir brauchen mehr POWER!"
Obwohl 80 PLUS Gold mittlerweile schon fast zum Standard im höheren Preis- und Leistungsbereich zählt, haben sich kleine PC-Netzteile mit dieser Zertifizierung noch immer kaum durchgesetzt. In der Leistungsklasse bis 500 W dominieren be quiet! und FSP den deutschen Markt, aber auch Super Flower bietet entsprechende Lösungen an. Von letzterer Marke stellen wir heute das Golden Green Pro mit 400 W Leistung vor. Dieses Modell haben wir über Amazon.de bezogen, um garantiert kein modifiziertes Muster zu erhalten. Auf den folgenden Seiten werden wir zeigen, ob die am Markt verfügbaren Modelle empfehlenswert sind. Wie immer wünschen wir viel Spaß beim Lesen!
Kaum ein Monat vergeht ohne größere Umbauten im Top-Management bei AMD. Heute vermeldet der Konzern, eine Nachfolgerin für Nigel Dessau als Senior Vice President und Chief Marketing Officer (CMO) gefunden zu haben. Colette LaForce, 39, wird diesen Posten künftig bekleiden und direkt an den Präsidenten und Chief Executive Officer Rory Read Bericht erstatten. In ihrer neuen Rolle soll LaForce das globale Marketing von AMD leiten, wozu die Erarbeitung von Marketingstrategien, das Branding, die interne und externe Komunikation, die Organisation von Firmenveranstaltungen, das Sponsoring und das Entertainment-Marketing gehören. Rory Read kommentiert die Neubesetzung wie folgt:
Zitat:
"Colette brings strong technology marketing and brand-building experience, a fresh perspective and a results-oriented approach that will strengthen AMDs global marketing organization. Her deep expertise will accelerate the revitalization of the AMD brand, amplifying our voice in the marketplace while helping position the company for long-term growth."
LaForce war zuvor bei Dell beschäftigt, wo sie mehrere Positionen im Marketing durchlief. Zuletzt war sie CMO der Dell Services Business Unit, welche allein einen Umsatz von 8 Milliarden US-Dollar erzielt. Vor ihrer Tätigkeit bei Dell war LaForce nahezu eine Dekade in Führungspositionen bei einer Vielzahl an Technologiefirmen und Risikokapitalgesellschaften angestellt. Hierzu zählen Rackable Systems (heute SGI) und Accenture. Sie wird ihren neuen Posten bei AMD am 14 Mai 2012 in Austin, Texas antreten
Senior Vice President und CMO Colette LaForce
Bereits gestern hat AMD zudem eine Börsenpflichtmitteilung veröffentlicht, wonach die Trennung von Emilio Ghilardi zum 7. Februar als Senior Vice President und Chief Sales Officer (CSO) mit einer Einmalzahlung von 800.000 US-Dollar einher ging.
Informativ sind dort insbesondere folgende Textstellen:
Zitat:
Abu Dhabi (Orochi-Rev C) support is mandatory
Zitat:
Abu-Dhabi is based on the Piledriver core will be available Q2 2012 and offers drop-in compatible part with 200 MHz performance uplift.
Wie jeder wissen sollte, basieren die aktuellen FX-Prozessoren, sowie die entsprechenden Server-Versionen Interlagos und Valencia, alle auf dem Orochi-Die. Aktuell ist die Version "B2". Abu-Dhabi und seine Desktop-Version "Vishera" sind damit eigentlich "nur" ein Update auf Revision Cx. Bereits früher berichteten wir über eine C0-Revision, der bei BOINC auftauchte. Wer mit den ganzen Codenamen durcheinander kommt, dem sei unsere Roadmap-Übersicht empfohlen. Eigentlich reicht es aber sich den Die-Codenamen "Orochi" zu merken und dann den gewünschten Sockel (G34/C32/AM3+) zu ergänzen. Aber zurück zu den Daten. Laut dem PDF bekommt Abu-Dhabi 200 MHz mehr Takt als die aktuellen Interlagos-Chips. Außerdem erfolgte die Auslieferung bereits im zweiten Quartal. Das überrascht etwas, denn das bedeutete, dass die Auslieferung spätestens im kommenden Monat erfolgen müsste. Vishera ist dagegen laut Gerüchten aus dem Februar erst fürs 3. Quartal geplant. Zusammengenommen kann man wohl davon ausgehen, dass Vishera damit eher Anfang des 3. Quartals erscheint. Für ein FX-8170-Modell bleibt also kein Platz mehr.
In Bezug auf die wahrscheinliche Taktfrequenz des Visheras muss man die 200 MHz des Abu-Dhabis als Untergrenze einordnen - schließlich besteht Abu-Dhabi aus zwei Orochi-Dies. Maximal wird man wohl auf +400 Mhz hoffen dürfen, womit man die werbewirksame 4,0-GHz-Marke erreichen könnte. Aber noch ist das pures Wunschdenken.
Man darf gespannt sein, ob AMD mit der Rev.-C des Orochi-Dies ein ähnliches Kunststück gelingt wie damals mit der Rev.-C des K10. Bald werden wir es wissen.
Dass AMDs Trinity-APU in den Startlöchern steht, dürfte dem aufmerksamen Leser nicht entgangen sein. Dennoch wollen wir noch einmal einen prüfenden Blick auf ein Modell der ersten Generation werfen. Die A4-3400 gehört zu den kleineren Llano-APUs und kostet im Handel gerade einmal 50 . Außerdem ist es das erste Silizium der Serie mit einer TDP von 65 W, das wir in die Hände bekommen konnten. Die bisherigen Prozessoren A6-3650, A8-3850 und A8-3870K wurden alle mit einer TDP von 100 W angegeben.
Wie viel die APU mit nur zwei Kernen und 2700 MHz zu leisten vermag und wie viel Leistung das System dabei aus der Steckdose zieht, werden wir auf den nächsten Seiten beleuchten.
Auf VR-Zone sind mehrere Bilder einer Trinity-Präsentation aufgetaucht. Die Präsentation der neuen APU, die mit ziemlich sicherer Wahrscheinlichkeit am 15. Mai erfolgt, rückt augenscheinlich immer näher, weswegen anscheinend auch der Informationsfluss immer breiter wird.
Die Angaben sind sehr detailliert, Einzelheiten sind der folgenden Tabelle zu entnehmen:
CPU
AMD A-Series
AMD A-Series
i3-2xxx
i3-3xxx
Codename
Trinity
Llano
Sandy-Bridge
Ivy-Bridge
Sockel
FM2
FM1
1155
1155
Threads
2 4
2 4
2 4
4 8
Herstellungsprozess
32nm SOI/HKMG
32nm SOI / HKMG
32nm HKMG
22nm HKMG
Chipfläche/Diegröße
246 mm²
228 mm²
131 mm²
160 mm²
L2-Cache-Größe
2 x 2 MB
4 x 1 MB
2 x 256 kB
4 x 256 kB
L3-Cache-Größe
/
/
3 MB
8 MB
Speicherkanäle
2xDDR3
2xDDR3
2xDDR3
2xDDR3
Max. Speicherstandard
DDR3-1866
DDR3-1866
DDR3-1333
DDR3-1600
int. PCIe Leitungen
24x PCIe 2.1
24x PCIe 2.1
16x PCIe 2.0
16x PCIe 3.0
TDP
100W
100W
65W
77W
Preis des Spitzenmodells
?
$115
~$140
~$330
DirectX-Standard
DX11
DX11
DX10.1
DX11
CPU-Verbesserungen Interessant wird es natürlich bei den erstmals eingesetzten Piledriver-Kernen, der 2. Generation der Bulldozer-Architektur. Viele Einzelheiten, wie z.B. der größere TLB, die größeren Scheduler-Windows, Befehlssatzerweiterungen wie FMA3 und F16C, zusätzliche Write Buffer für den L2 oder auch die DIV-Einheit waren schon vorher durch das AMD Optimization Guide oder durch eigene Recherche bekannt, die durch den aktuellen Foliensatz nun bestätigt wurden. Merkwürdig ist nur die aufgeführte ISA-Erweiterung "AVX 1.1", die es laut Intel nicht geben dürfte. Da gleichzeitig AMDs eigene Erweiterungen XOP und FMA4 nicht aufgeführt werden, ist zu vermuten, dass AMD diese in AVX 1.1 umbenannt hat.
Einzig das Front-End, in dem die Daten in ein Bulldozer-Modul eingelesen werden, war ein Buch mit sieben Siegeln. Nun wird das Geheimnis etwas gelüftet und man erfährt erste Änderungen in folgendem Bild:
Es darf darauf gehofft werden, dass dort einige Schwachstellen, die z.B. durch den Informatikprofessor Agner Fog angemahnt werden, behoben oder doch zumindest abgemildert werden. (Eine Zusammenfassung der Schwachstellen gab es in unserer alten Meldung: Bulldozer-Architektur unter der Lupe: Schwachstellen identifiziert).
Eine der Schwachstellen war das sogenannte "Instruction-Window". Das ist ein Paket an x86-Befehlen, die von der "Fetch-Unit" geschnürt werden und darauf warten, durch den Dekoder in interne µOps dekodiert zu werden. Wie beim K10 werden auch beim Bulldozer 32 Byte pro Takt aus dem L1-Instruction-Cache eingelesen, aber bei Bulldozer teilen sich die 32 Byte dann eben auf zwei Threads und damit auch auf zwei Instruction Windows à 16 Byte auf. 16 Byte sind für AMD deshalb ein Rückschritt. Aktuelle Intel-CPUs holen sich pro Takt zwar auch nicht mehr, allerdings wird Intels Dekoder durch den Loop-Stream-Detektor (seit der Penryn-Generation, verbessert im Nehalem) und den großen µOp-Puffer (seit Sandy-Bridge) stark entlastet. Mit solchen Finessen kann laut den aufgetauchten Folien auch Piledriver nicht aufwarten, aber immerhin wird der Flaschenhals etwas vergrößert. Um wieviel ist dabei die Frage. Hoffen wir das Beste und erwarten einmal die vom K10 bekannten 32 Byte pro Fenster / Thread auch für Piledriver. Viel hängt aber auch davon ab, wieviel Byte pro Takt eingelesen werden. Bleibt es weiterhin bei 32 Byte brächten zwei 32 Byte Fenster keinen großen Vorteil. Zu guter Letzt darf man außerdem nicht vergessen, dass es weiterhin nur 4 Dekoder gibt. Das Maximum bleibt also weiterhin bei zwei x86 Instruktionen pro Takt, pro Thread, aber mit einem größerem Instruktion-Window stellt man sicher, dass dieses Maximum auch öfters erreicht werden kann.
Zusätzlich gab es im Front-End noch Feintuning an der Sprungvorhersage-Logik, diese kann mehr Einträge umfassen, was man auch im Die-Foto erkennen kann.
Turbo Modi Beispielhaft für die ganze Trinity-Generation gibt es eine Folie für die Turbomodi des A10-4600M-Exemplars:
Wie man sehen kann, beträgt der maximale Turbo mit einem Thread 3,2 Ghz, ohne Grafiklast werden noch 2,7 GHz erzielt, mit Grafiklast dagegen muss man mit 2,3 GHz Prozessortakt auskommen.
Nicht viel Neues gibt es vom Grafikteil der neuen APU zu berichten. 384 Shader nach der altbekannten VLIW4-Bauart, die erst- und einmalig in der HD6900-Generation eingesetzt war. Eine APU mit den neuen GNC-Architektur gibt es erst nächstes Jahr unter dem Codenamen Kaveri. Interessant ist vielleicht ein Detail: Laut obiger Folie unterstützt die APU Off-Chip-Speicher, wodurch die Tessellation-Leistung gesteigert wird. Dabei handelt es sich aber um keinen extra Chip, sondern nur um einen Speicherbereich im normalen RAM. Oben rechts im Eck des Bildes sieht man auch die unterstützte PCIe Version. Leider scheint Trinity nur mit PCIe 2.1 und nicht schon mit PCIe 3.0 zu kommen - sofern es sich nicht um einen Copy/Paste-Fehler handelt. Wie schon der Vorgänger Llano hat auch Trinity 24 PCIe-Leitungen.
Stromverbrauch AMD rühmt sich besonders ob des konkurrenzfähigen Stromverbrauchs, laut eigenen Aussagen würde man jetzt nicht nur mehr hinterher trotten:
Fazit Alle Neuerungen auf einen Blick sieht man in der folgenden Folie, bei dem unbeschrifteten Bereich links oben, zwischen DDR3 und dem linken L2-Cache, handelt es sich vielleicht um die VCE-Schaltkreise:
Für die CPU-Leistungskrone wird es sicherlich nicht reichen, jedoch sollte das Gesamtpaket aus leicht gesteigerter Rechenleistung durch die Bulldozerkerne und v.a. durch höhere Taktraten sowie der konkurrenzlosen GPU-Leistung eine sehr attraktive Kombination sein. Insbesondere in Bereichen, in denen man keinen Platz für eine zusätzliche Grafikkarte hat, aber nicht auf eine gute GPU verzichten kann, sollte Trinity ein attraktives Produkt sein. Alle Folien gibt es in Großansicht in unserer Bildergalerie.





























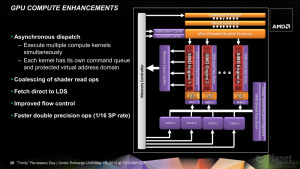
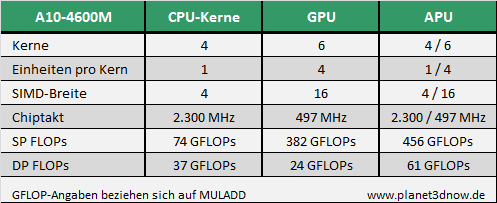
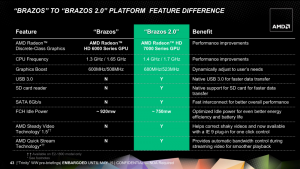
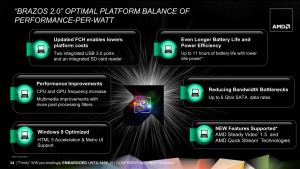
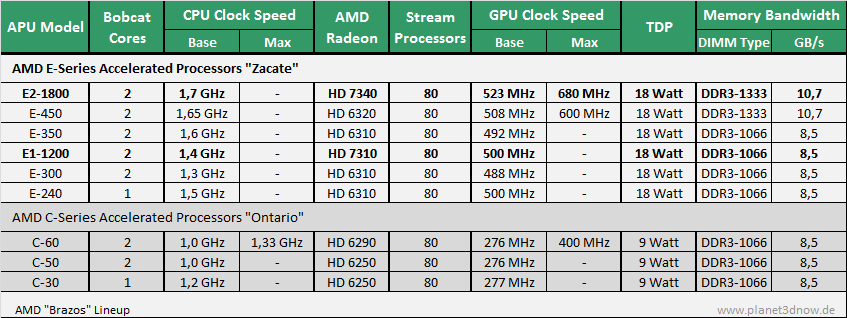






Diesen Artikel bookmarken oder senden an ...